Algorithms for Speeding up Distance-Based Outlier Detection
Shared by Kanishka Bhaduri, updated on Aug 15, 2011
Summary
- Author(s) :
- Kanishka Bhaduri, Bryan Matthews, C. Giannella
- Abstract
The problem of distance-based outlier detection is difficult
to solve efficiently in very large datasets because of potential
quadratic time complexity. We address this problem and
develop sequential and distributed algorithms that are significantly
more efficient than state-of-the-art methods while
still guaranteeing the same outliers. By combining simple
but effective indexing and disk block accessing techniques,
we have developed a sequential algorithm iOrca that is up to
an order-of-magnitude faster than the state-of-the-art. The
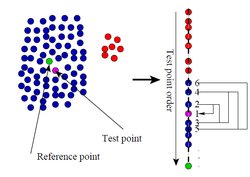
indexing scheme is based on sorting the data points in order
of increasing distance from a fixed reference point and
then accessing those points based on this sorted order. To
speed up the basic outlier detection technique, we develop
two distributed algorithms (DOoR and iDOoR) for modern
distributed multi-core clusters of machines, connected
on a ring topology. The first algorithm passes data blocks
from each machine around the ring, incrementally updating
the nearest neighbors of the points passed. By maintaining
a cutoff threshold, it is able to prune a large number
of points in a distributed fashion. The second distributed
algorithm extends this basic idea with the indexing scheme
discussed earlier. In our experiments, both distributed algorithms
exhibit significant improvements compared to the
state-of-the-art distributed methods.
- Publication Name
- N/A
- Publication Location
- SIG KDD
- Year Published
- 2011
Files
|
600.4 KB | 326 downloads |